11 maart 2026
Hoe we voorkomen dat AI 'vergeet' bij het leren van nieuwe dingen
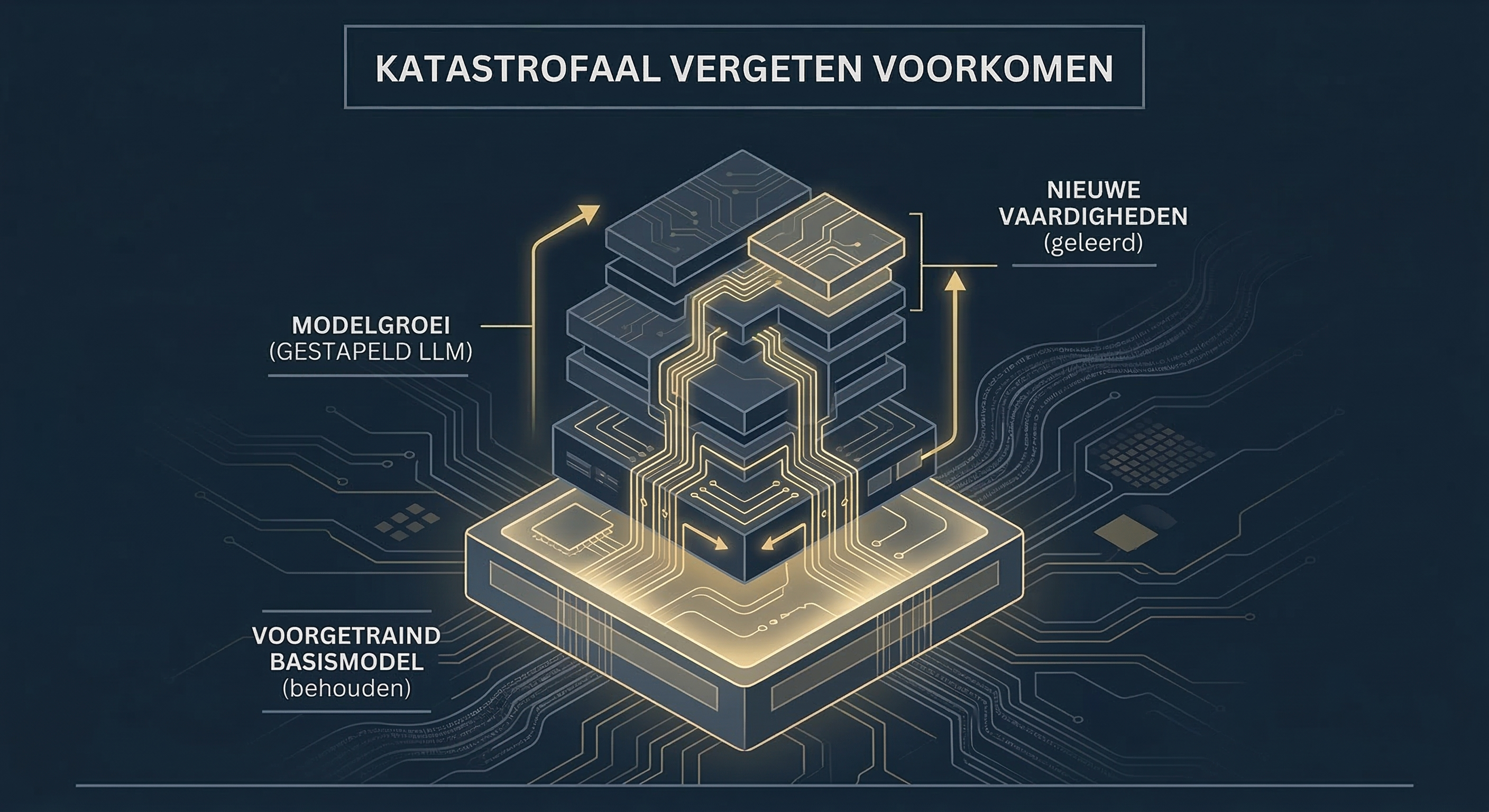
Kunstmatige intelligentie ontwikkelt zich in een razend tempo. Grote taalmodellen, de complexe technologie achter de bekende slimme chatbots, worden voortdurend getraind om nieuwe vaardigheden op te pikken en actuele informatie te verwerken. Toch lopen wetenschappers tegen een opmerkelijk en hardnekkig probleem aan wanneer ze deze systemen continu nieuwe dingen proberen te leren. Dit probleem staat in de wetenschap bekend als catastrofaal vergeten. Stel je voor dat je intensief oefent om vloeiend Spaans te spreken, maar als direct gevolg daarvan plotseling vergeet hoe je moet fietsen of rekenen. Dit is in wezen wat er gebeurt in de ‘hersenen’ van een neuraal netwerk: wanneer een AI-model wordt bijgetraind op nieuwe, specifieke taken, overschrijft het vaak per ongeluk de fundamentele kennis die het eerder met veel moeite had opgedaan.
Een recente wetenschappelijke publicatie van onderzoekers Ege Süalp en Mina Rezaei, getiteld “Mitigating Catastrophic Forgetting in Continual Learning through Model Growth”, werpt een interessant nieuw licht op een mogelijke oplossing voor dit fenomeen. In dit onderzoek zoeken de auteurs naar een effectieve methode om AI-modellen continu te laten leren zonder dat hun basale denkvermogen afbrokkelt. Het trainen van enorme taalmodellen is ontzettend kostbaar en vraagt astronomisch veel computerrekenkracht. Om die reden zochten de onderzoekers naar een veel efficiëntere manier om deze systemen te trainen en tegelijkertijd hun digitale geheugen te beschermen tegen het overschrijven van oude, nuttige vaardigheden.
Bouwen op een stevige fundering
De innovatieve oplossing die zij onderzochten, wordt modelgroei genoemd. In plaats van een gigantisch nieuw computermodel volledig vanaf de basis op te bouwen en te trainen, beginnen de onderzoekers met een kleiner AI-model dat al uitstekend getraind is in de basisbeginselen. Dit kleinere basismodel wordt vervolgens systematisch uitgebreid en vergroot om een zwaarder systeem te vormen. De onderzoekers noemen dit vergrote systeem een Stack LLM.
Je kunt deze strategie het beste vergelijken met het uitbreiden van een gebouw: in plaats van een bestaand en goed functionerend huis volledig af te breken om een grotere variant te bouwen, voeg je simpelweg extra verdiepingen toe op de reeds stevige en bewezen fundering. Deze aanpak bespaart niet alleen enorm veel tijd en stroom, maar blijkt ook verrassend positieve effecten te hebben op de manier waarop het model eerdere informatie vasthoudt.
Veelbelovende resultaten met een keerzijde
Om in de praktijk te testen of deze opgebouwde modellen daadwerkelijk beter presteren, lieten de onderzoekers zowel een traditioneel getraind model als een ‘gegroeid’ model een lange reeks nieuwe, complexe taken uitvoeren. Deze taken testten diverse aspecten, waaronder specifieke vakkennis, logisch redeneren en begrijpend lezen. De resultaten uit het experiment waren veelbelovend. Het bleek dat beide modellen er goed in slaagden om nieuwe feitenkennis succesvol in zich op te nemen. Echter, bij het traditionele AI-model begon de prestatie op het gebied van logisch nadenken en begrijpend lezen na verloop van de trainingen sterk te verslechteren, wat duidt op precies dat ongewenste catastrofale vergeten. Het vergrote model bleek hier aanzienlijk beter tegen bestand. Vooral op het gebied van begrijpend lezen wist dit model zijn eerder geleerde vaardigheden sterk vast te houden en presteerde het beduidend beter dan de traditionele variant.
Toch benadrukken de onderzoekers dat deze nieuwe ontwerpmethode niet zonder nadelen is. Tijdens de evaluaties ontdekten zij namelijk een fascinerend en lastig compromis op het gebied van sociale vooroordelen. Waar het traditionele model tijdens het verwerken van nieuwe taken langzaam maar zeker steeds neutraler en minder bevooroordeeld werd in zijn antwoorden, bleef het gegroeide model juist heel sterk vasthouden aan de initiële patronen die het tijdens zijn allereerste trainingsfase had meegekregen. Het percentage bevooroordeelde reacties bleef bij dit model steken op ruim zestig procent. Dit toont aan dat het structureel vasthouden van oude kennis een tweesnijdend zwaard is in de wereld van AI: het model onthoudt zijn nuttige intellectuele vaardigheden veel beter, maar wist tegelijkertijd zijn ongewenste fouten en vooroordelen aanzienlijk minder makkelijk uit.
Conclusie
Al met al biedt dit onderzoek een bijzonder waardevolle stap voorwaarts in de ontwikkeling van duurzamere en slimmere kunstmatige intelligentie. Door digitale modellen stapsgewijs te laten groeien in plaats van hun brein steeds volledig te herschrijven, kunnen ingenieurs systemen creëren die efficiënter leren en hun waardevolle basisvaardigheden beter beschermen. De grote uitdaging voor de nabije toekomst zal liggen in het vinden van een perfecte balans waarbij nuttige kennis stevig behouden blijft, terwijl de ongewenste vooroordelen alsnog succesvol kunnen worden weggeschaafd.
Referentie naar het originele artikel: Süalp, E., & Rezaei, M. (2025). Mitigating Catastrophic Forgetting in Continual Learning through Model Growth. arXiv preprint. Volledig artikel beschikbaar via: https://arxiv.org/pdf/2509.01213
Deel dit artikel